Enterprise AI Is Starting to Institutionalize Disagreement
Enterprise AI is shifting away from the one-box oracle fantasy and toward built-in critique, comparison, and review. The deeper product change is that workplace software is starting to formalize disagreement as part of how trust gets built.
For years, AI product marketing has been built around a childish fantasy.
Ask one system a question. Get one answer back. Trust the machine if it sounds smooth enough.
That was always a flimsy model of intelligence. It was especially flimsy for work.
Real knowledge work does not run on solitary certainty. It runs on drafts, objections, second looks, skeptical colleagues, review layers, and the occasional useful argument that saves everyone from marching confidently in the wrong direction.
Now enterprise software is starting to admit that.
Microsoft’s latest Microsoft 365 Copilot Researcher capabilities, including Critique and Council, point to a bigger shift than a routine feature drop. The important move is not that one more AI tool can produce a better memo. It is that enterprise software is beginning to formalize disagreement as part of the product itself.
That matters because the next phase of AI at work may depend less on making machines sound authoritative and more on making them procedurally contestable.
The more serious enterprise AI products become, the less they can behave like lone geniuses. They have to behave more like institutions.
The singular-oracle model was never built for serious work
A lot of consumer AI design trained people to think in a strangely theatrical way.
There is the assistant.
It knows.
You ask.
It answers.
That is a decent interface fantasy for trivia, drafting help, or lightweight search. It is not how important decisions usually get made inside organizations.
In actual workplaces, trust does not come from one fluent answer appearing on a screen. It comes from a structure around the answer. Someone writes the first pass. Someone pressure-tests assumptions. Someone checks whether the sources are thin. Someone else notices the recommendation sounds elegant but would fall apart once it touches budget, policy, or operations.
That social machinery can be annoying. It also prevents a lot of expensive stupidity.
What Microsoft is signaling with multi-model comparison, critique layers, and agreement-versus-divergence summaries is that AI products are beginning to absorb some of that machinery. The system no longer needs to pose as a single oracle. It can act more like a staged internal process.
That is not a cosmetic change.
It is a philosophical one.

Software is borrowing the shape of institutions
The most interesting part of this shift is not “multiple models are better than one.” That line is fine as far as it goes, but it undersells what is happening.
The deeper change is structural.
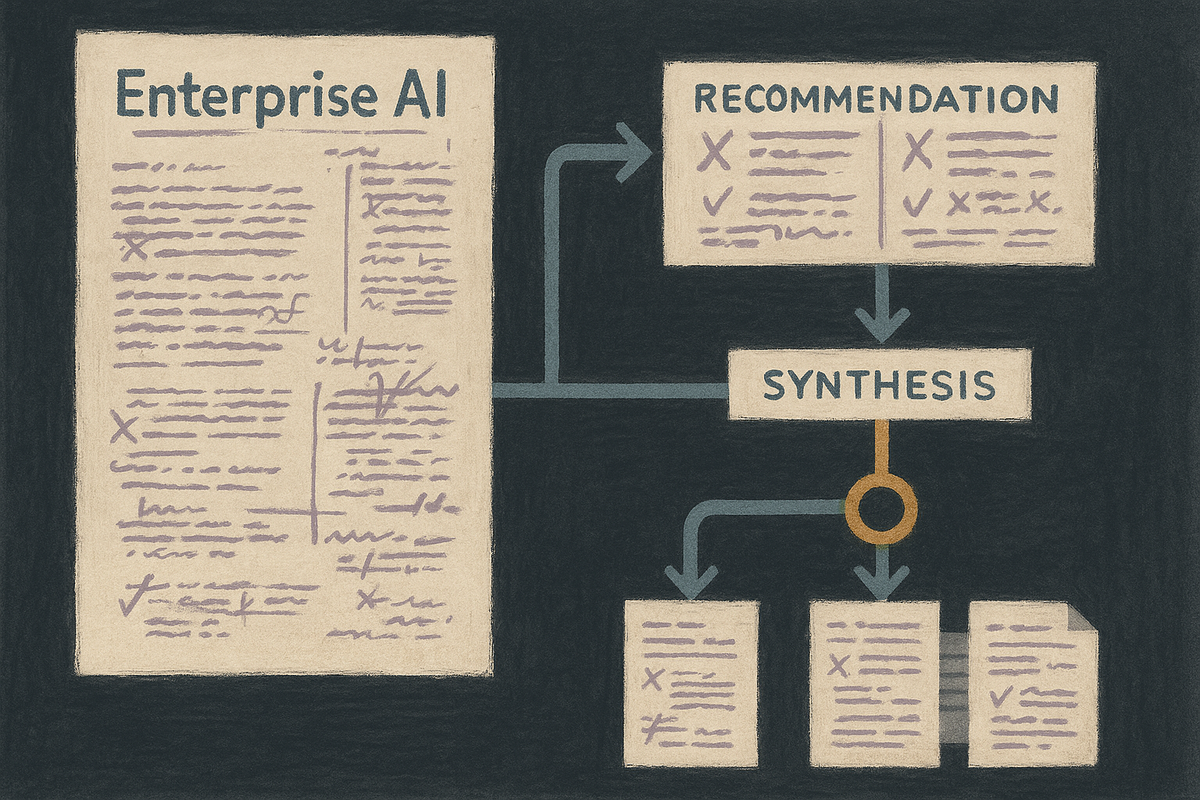
Work software is starting to borrow the organizational forms humans use when confidence matters. One system generates. Another critiques. A set of models compares options side by side. Agreement is surfaced. Disagreement is surfaced. A synthesis gets built from competing views instead of being handed down like a digital commandment.
That starts to look less like a chatbot and more like a committee.
Normally “committee” is not a flattering word in software. It suggests delay, mush, and the slow death of conviction in conference rooms with bad coffee. But committees persist for a reason: when stakes rise, institutions usually want visible procedure, not just raw output.
Constellation Research made that subtext clearer than Microsoft’s own product language did. Its read on the launch was not merely that a multi-model setup can improve quality. It was that comparison and synthesis are becoming product behavior. The system begins to show its work in a form managers, cautious operators, and procurement teams can actually narrate inside a company.
That is where enterprise AI is heading.
The product is no longer only the answer.
The product is the review structure around the answer.
This is how AI becomes governable inside companies
One reason generative AI has felt simultaneously useful and unstable is that it arrived in office life with a suspiciously casual trust model.
A system could write, summarize, recommend, and sound confident at industrial speed, while the burden of verification quietly got pushed back onto the worker using it. The machine looked authoritative. The human remained accountable. Convenient arrangement for the software vendor, if we are being honest.
Procedural disagreement changes that balance a little.
When a tool explicitly stages critique, comparison, and revision, it becomes easier to treat AI output as inspectable work product rather than polished verdict. That is healthier. It fits the way organizations actually manage risk. It also gives managers and workers a story they can live with: the system is not replacing judgment so much as simulating some of the process that judgment usually requires.
That does not eliminate error. It may create new forms of error, including false confidence in machine consensus. But it is still an advance over the one-box system that says, in effect, “here is your answer, good luck with the consequences.”
If AI is going to survive contact with procurement, compliance, legal review, regulated industries, and large-company politics, it was always going to need more procedure.
Now the procedure is arriving.

Managed disagreement can improve trust. It can also domesticate it.
There is an obvious optimistic read here.
If enterprise tools can separate generation from evaluation, compare multiple approaches, and show users where systems diverge, then maybe organizations get better outputs with less blind trust. Maybe workers become less dependent on one machine’s tone and more able to examine the shape of uncertainty. Maybe AI becomes less mystical and more boring in the best possible way.
That would be progress.
But there is a more complicated read too.
Once disagreement becomes productized, institutions may start treating machine-managed consensus as a substitute for human judgment rather than as support for it. The software says three systems broadly agree, one system objects, and the summary recommends path A. That can feel reassuring enough to end the discussion even when the dissent is the thing that mattered.
Organizations are very capable of mistaking process for wisdom.
They have had centuries of practice.
So the real question is not whether AI should critique itself. Of course it should. The real question is who gets to interpret the critique, who notices when the dissent is right, and whether workers are being trained to think with the system or simply to defer to a more elaborate version of it.
A machine committee can still be a machine committee.
It can still converge on the wrong answer with beautiful formatting.
The next workflow battle is about where judgment lives
This is why the shift matters beyond Microsoft.
Enterprise AI is beginning to move from answer generation into workflow design. The more software starts embedding author-reviewer-committee dynamics, the less the market is about which model sounds smartest in isolation and the more it is about where judgment is located inside the product.
Is the worker expected to inspect every output manually?
Is the system doing its own adversarial checking?
Is disagreement visible or hidden?
Is confidence earned through process or faked through tone?
Those are workflow questions.
They are also power questions.
Because once companies build machine review structures into everyday software, they are not just buying intelligence. They are buying a theory of how decisions should move.
That theory will shape pacing, accountability, escalation, and the practical meaning of expertise at work.
The old promise of AI was: ask better questions, get faster answers.
The new promise is becoming: put your work inside a managed system of synthetic review.
That is a much bigger change.
The future office may trust procedure before it trusts brilliance
For a while, AI companies sold a very Silicon Valley version of intelligence: fast, singular, dazzling, and vaguely above institutional friction.
But large organizations rarely run on brilliance alone. They run on procedure, evidence trails, role boundaries, and structured disagreement that can be defended after the fact. They want outputs, yes, but they also want process they can point to when something goes wrong.
That is why this turn toward critique and council matters. It suggests enterprise AI is growing out of its oracle phase.
The next useful systems may not be the ones that sound most genius. They may be the ones that feel most governable.
That is less glamorous than the industry’s old sales pitch.
It is also more believable.
Because in real institutions, trust is rarely built by the loudest answer in the room.
It is built by the structure that lets people challenge it before they act on it.
Software is finally starting to learn that.
And once it does, the AI product story changes.
Not from machine to human.
From machine to institution.
References
- Microsoft 365 Blog, “Copilot Cowork: Now available in Frontier,” March 30, 2026. https://www.microsoft.com/en-us/microsoft-365/blog/2026/03/30/copilot-cowork-now-available-in-frontier/
- Microsoft Tech Community, “Introducing multi-model intelligence in Researcher,” March 30, 2026. https://techcommunity.microsoft.com/blog/microsoft365copilotblog/introducing-multi-model-intelligence-in-researcher/4506011
- Constellation Research, “Microsoft 365 Copilot’s Researcher agent goes multi-model,” March 30, 2026. https://www.constellationr.com/insights/news/microsoft-365-copilots-researcher-agent-goes-multi-model